Within the brains of the PowerPC G5 is more processing
power than you’ve ever experienced from a desktop chip. Its massively
parallel circuits are capable of handling multiple assorted tasks at
the same time. Called an execution core, it’s where your Mac does all
its thinking.
The design was derived from IBM’s 64-bit POWER4 processor — recipient
of the Microprocessor Report’s 2001 Analyst’s Choice Award for Best
Workstation/Server Processor, which recognizes excellence in
semiconductor technology innovation, design and implementation. With
two double-precision floating-point units, advanced branch prediction
logic and a high-bandwidth frontside bus, the POWER4 drives IBM’s
successful eBusiness servers.
To that superscalar, superpipelined execution core, Apple and IBM added
the Velocity Engine to the design, so that every Mac OS X application
would run efficiently. Additionally, the PowerPC G5 features processing
innovations that optimize the flow of data and instructions — meaning
the PowerPC G5 can pump through more than 200 in-flight instructions at
a time, a whopping 71% more than the 32-bit Pentium 4.
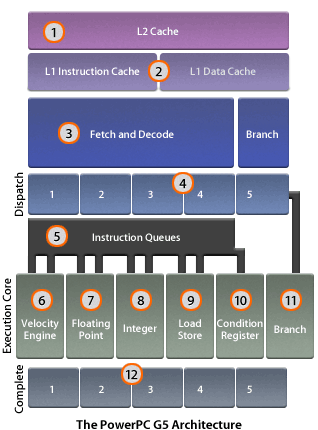
 L2Cache L2Cache
512K of L2 cache provide the execution core with ultrafast 64-MBps
access to data and instructions.
 L1 Cache L1 Cache
Instructions are prefetched from the L2 cache into a large,
direct-mapped 64K L1 cache at 64 GBps. In addition, 32K of L1 data
cache can prefetch up to eight active data streams simultaneously.
 Fetch and Decode Fetch and Decode
As they are accessed from the L1 cache, up to eight instructions per
clock cycle are fetched, decoded and divided into smaller,
easier-to-schedule operations. This efficient preparation maximizes
processing speed as instructions are dispatched into the execution core
and data is loaded into the large number of registers behind the
functional units.
 Dispatch Dispatch
Before instructions are dispatched into the functional units, they are
arranged into groups of up to five. Within the core alone, the PowerPC
G5 can track up to 20 groups at a time, or 100 individual instructions.
This efficient group-tracking scheme enables the PowerPC G5 to manage
an unusually large number of instructions “in flight”: 20 instructions
in each of the five dispatch groups and an additional 100-plus
instructions in the various fetch, decode and queue stages.
 Queue Queue
Once an instruction group is dispatched into the execution core, it is
broken into individual instructions, which proceed to the appropriate
functional unit. Each functional unit has its own dedicated queue,
where multiple instructions are arranged for processing in whatever
order is required.
 Optimized Velocity Engine Optimized Velocity Engine
The PowerPC G5 uses an optimized dual-pipelined Velocity Engine with
two independent queues and dedicated 128-bit registers and data paths
for efficient instruction and data flow. This vector processing unit
accelerates data manipulation by applying a single instruction to
multiple data at the same time, known as SIMD processing. The Velocity
Engine in the PowerPC G5 uses the same set of 162 instructions as in
the PowerPC G4, so it can run — and accelerate — existing Mac OS X
applications already optimized for the Velocity Engine.
 Two Double-Precision
Floating-Point Units Two Double-Precision
Floating-Point Units
Two double-precision floating-point units provide the precision
required for highly complex scientific computations. Although 32-bit
processors are able to execute double-precision 64-bit calculations by
cycling through the floating-point math unit multiple times, a
double-precision math unit on a 64-bit processor can complete the same
calculation in a single clock cycle. Two double- precision
floating-point units let the G5 complete at least two 64-bit
mathematical calculations per clock cycle. This dramatically
accelerates highly complex computations critical in genome-matching
applications and in many of the filters used to manipulate or render 3D
graphics and video content. |
 |
 Two Integer Units Two Integer Units
Integer units perform simple integer mathematics — such as add,
subtract and compare — which are commonly used in many basic computer
functions, as well as in imaging, video and audio applications. The
PowerPC G5 has two integer units capable of a broad range of simple and
complex instructions involving both 32-bit or 64-bit calculations.
What’s more, they take full advantage of the processor’s 64-bit
registers and data paths to complete 64-bit integer calculations in a
single pass.
 Load/Store Load/Store
At the same time as instructions are queued, the load/store units load
the associated data from L1 cache into the data registers behind the
units that will be processing the data. After the instructions
manipulate the data, these units store it back to L1 cache, L2 cache or
main memory. Each functional unit is generously equipped with 32
registers that are 128-bit wide on the Velocity Engine and 64-bit wide
on the floating-point units and the integer units. With two load/store
units, the PowerPC G5 is able to keep these registers filled with data
for maximum processing efficiency.
 Condition Register Condition Register
This special 32-bit register summarizes the states of the
floating-point and integer units. The condition register also indicates
the results of comparison operations and provides a means for testing
them as branch conditions. By bridging information between the branch
unit and other functional units, the condition register improves the
flow of data throughout the execution core.
 Three Component
Branch Prediction Logic Three Component
Branch Prediction Logic
The PowerPC G5 usually knows the answer before it asks the question,
using branch prediction and speculative operation to increase
efficiency. Like finishing someone else’s sentences, branch prediction
anticipates which instruction should go next, and speculative operation
causes that instruction to be executed. If the prediction is correct,
the processor works more efficiently — since the speculative operation
has executed an instruction before it’s required, as with a
conversation that seems to be a mind meld. If the prediction is
incorrect, the processor must clear the unneeded instruction and
associated data, resulting in an empty space called a pipeline bubble.
Pipeline bubbles reduce performance as the processor marks time waiting
for the next instruction, not unlike wasting time hearing how very
wrong your assumptions were. The G5 can predict branch processes with
an accuracy of up to 95%, allowing the chip to efficiently use every
processing cycle.
 Complete Complete
When operations on the data are complete, the PowerPC G5 recombines the
instructions into the original groups of five and the load/store units
store the data in cache or main memory for further processing.
|

